|
AI 2.0 (GenAI): Currently I build and deploy data algorithms for the multimodal data pipeline at Kling Team , covering multimodal understanding, multimodal data quality grading, and multimodal retrieval systems that support large-scale generative model training. My work focuses on building robust data-centric infrastructure for multimodal foundation models, including preference data construction, quality-aware data selection, and retrieval-aligned optimization to improve training efficiency and model performance. AI 1.0 (Perception & Recognition): Previously, at Alibaba's AutoNavi Vision Technology Center, I was responsible for large-scale perception algorithms deployed nationwide, including detection, segmentation, recognition, and 3D reconstruction systems, along with full data-closed-loop optimization. My work bridged algorithm research and production deployment in real-world geographic and spatial intelligence systems. I am looking for self-motivated interns for mulimodal understanding and generation research! If you are interested in internship at Kling or collaboration of research, please email me. |

|
|
|
(See full list at Google Scholar, * indicates equal contribution, † indicates project lead.) I obtained my Master degree from School of Artificial Intelligence, Beijing University of Posts and Telecommunications (BUPT), co-supervised by Dr. Chen Li, Prof. Si Li and Prof. Boxin Shi. My research interests lie in multimodal understanding, with an emphasis on integrating vision, audio, language, and physical cues for grounded reasoning. Recently, I have focused on physics-aware and generative approaches to help models understand the physical structure and dynamics of the world, enabling richer multimodal perception and reasoning. |
|
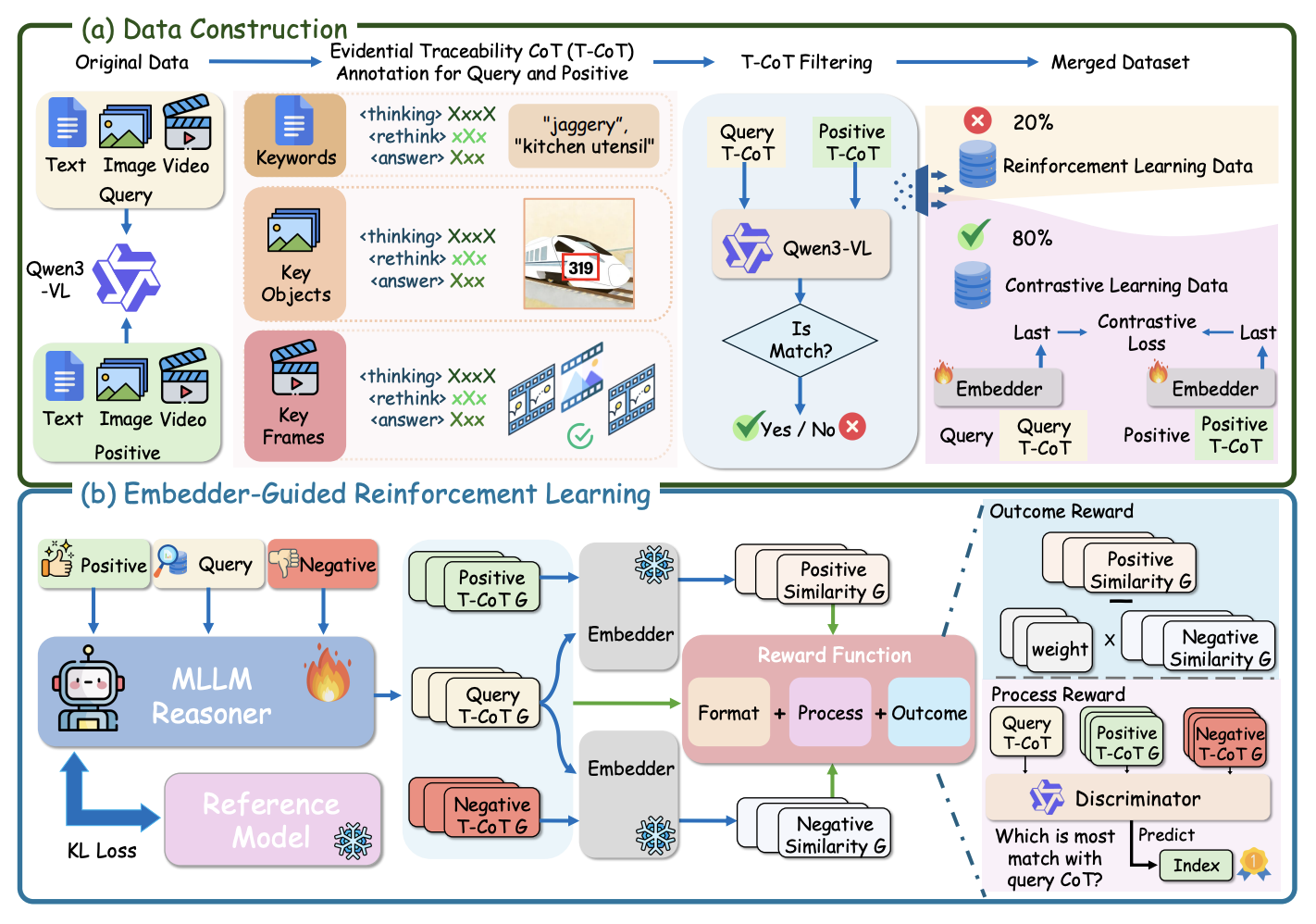
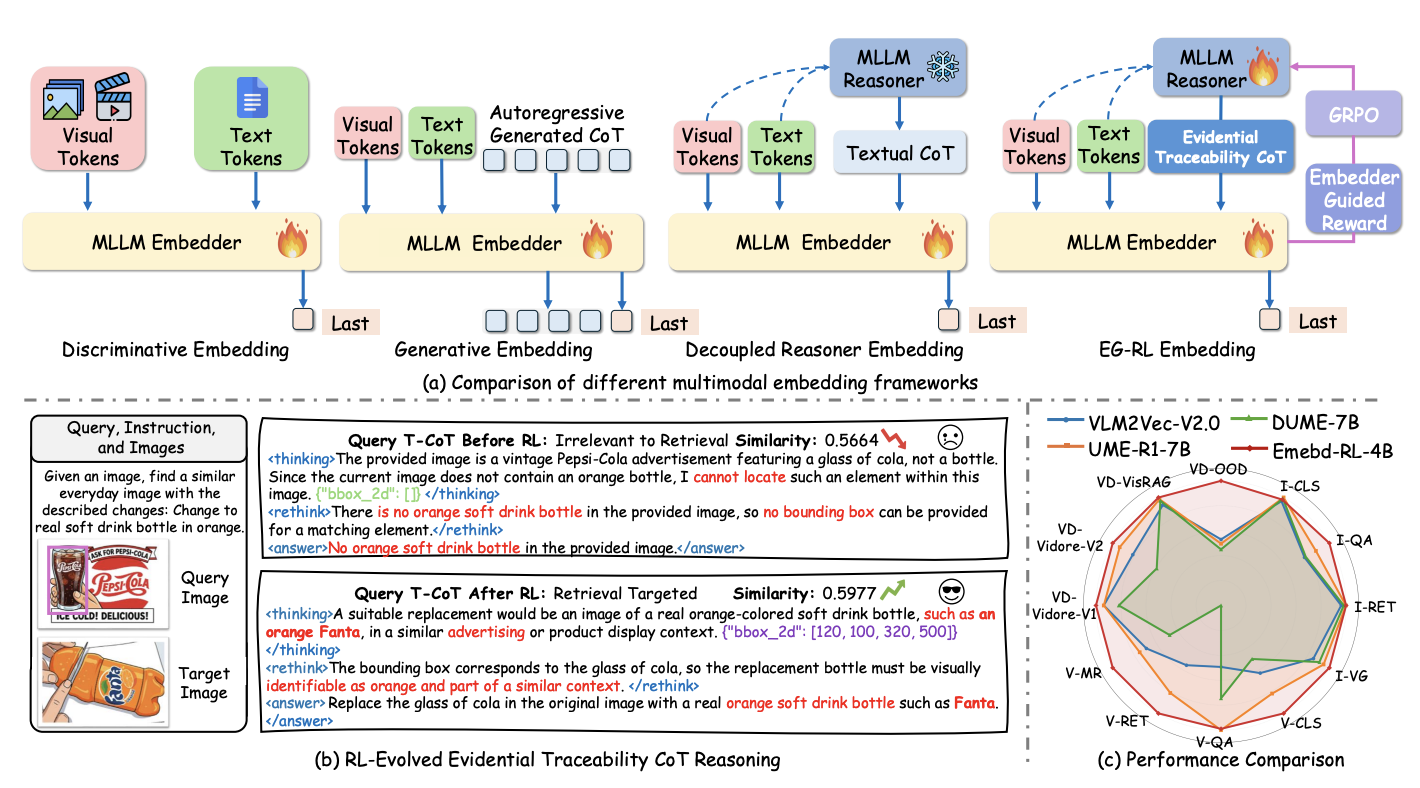
Haonan Jiang*, Yuji Wang*, Yongjie Zhu†, Xin Lu, Wenyu Qin, Meng Wang, Pengfei Wan, Yansong Tang arXiv, 2026 [paper] [project] We propose a reasoning-driven Universal Multimodal Embedding framework that leverages Embedder-Guided Reinforcement Learning to generate retrieval-aligned, evidential Traceability CoTs, significantly improving cross-modal semantic consistency, fine-grained matching, and benchmark performance under limited computational resources. |
|
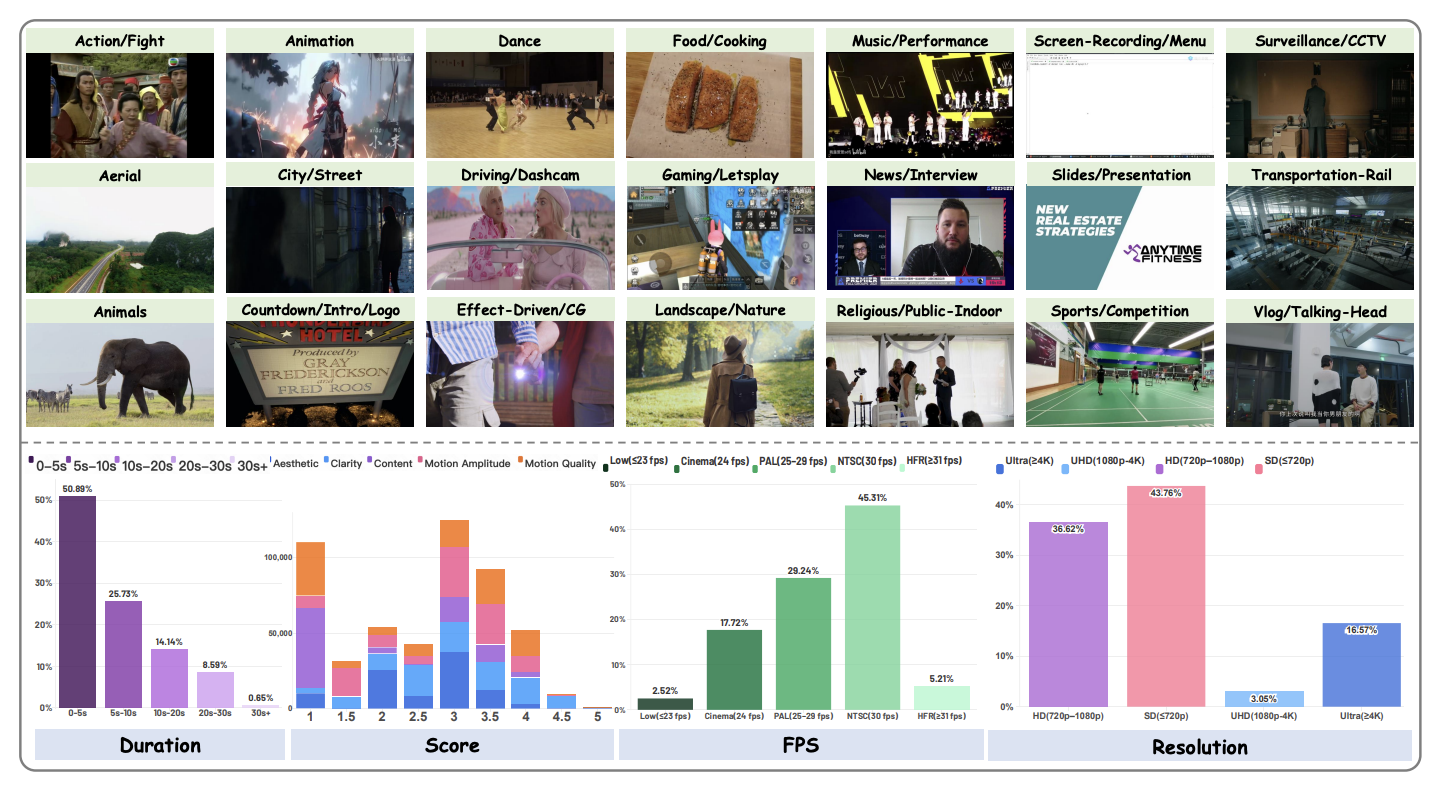
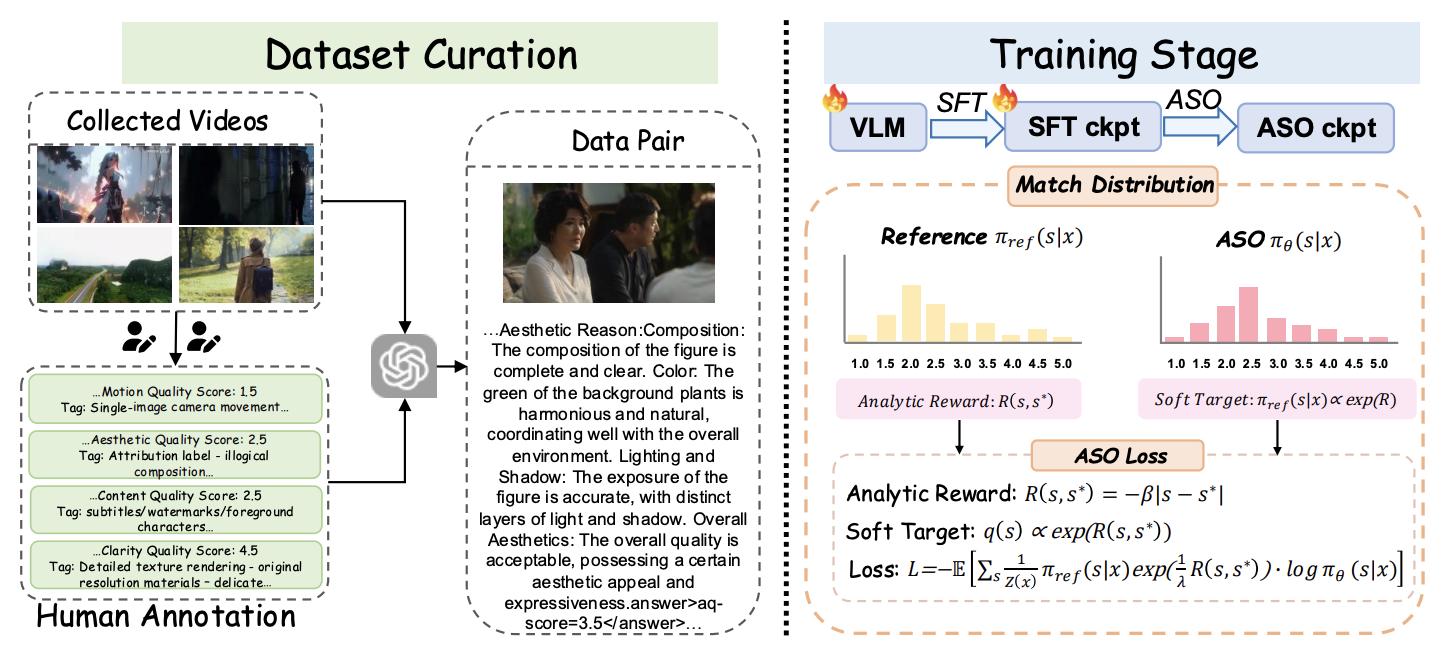
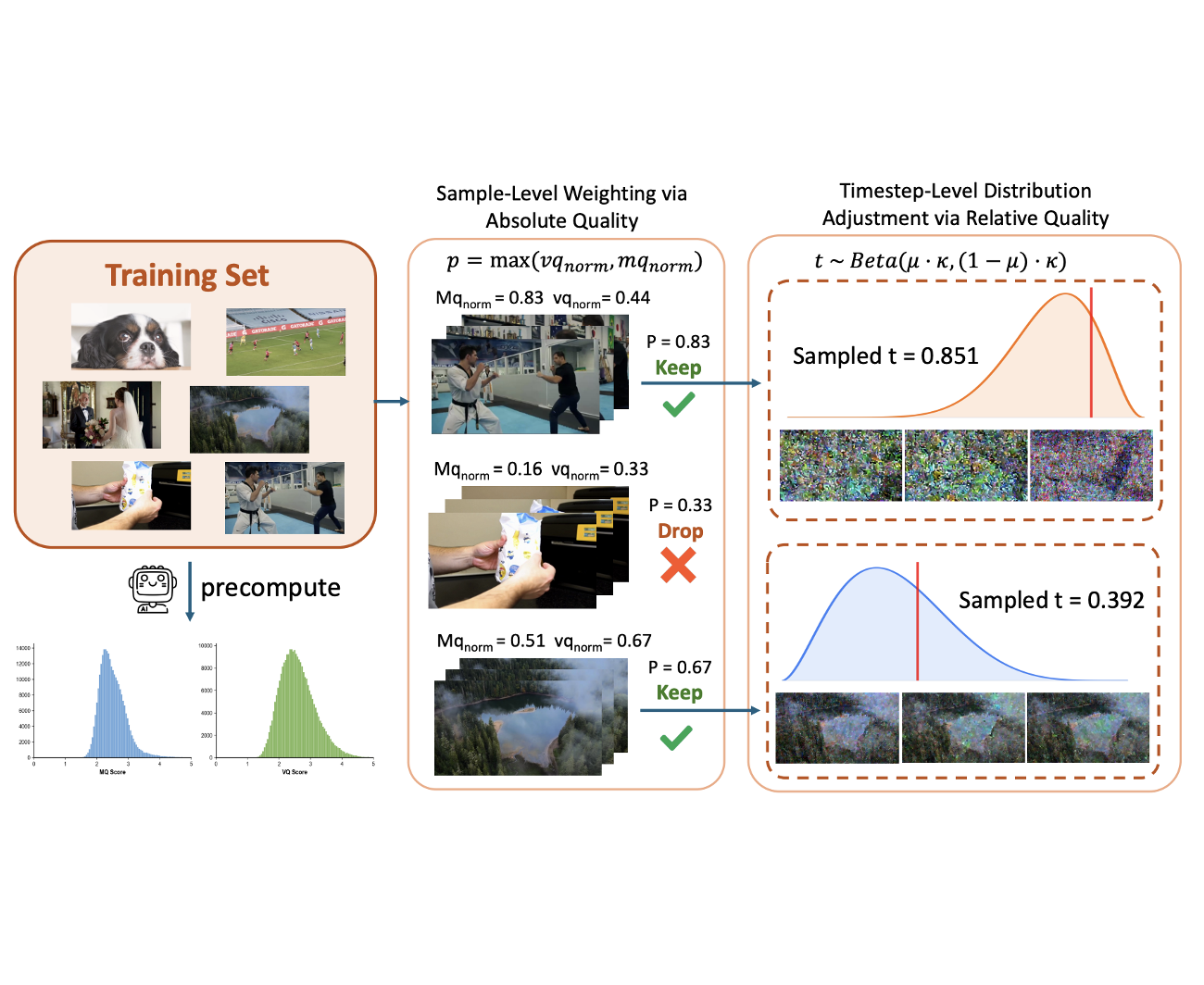
Boda Lin, Yongjie Zhu†, Wenyu Qin, Meng Wang, Pengfei Wan arXiv, 2026 [paper] [project] We introduce UltraVQA, a large-scale multi-dimensional video quality assessment dataset with rich human and GPT-augmented annotations, and propose Analytic Score Optimization (ASO), a theoretically grounded post-training objective that models quality assessment as a regularized decision process, achieving superior performance and lower MAE compared to existing closed- and open-source baselines. |
|
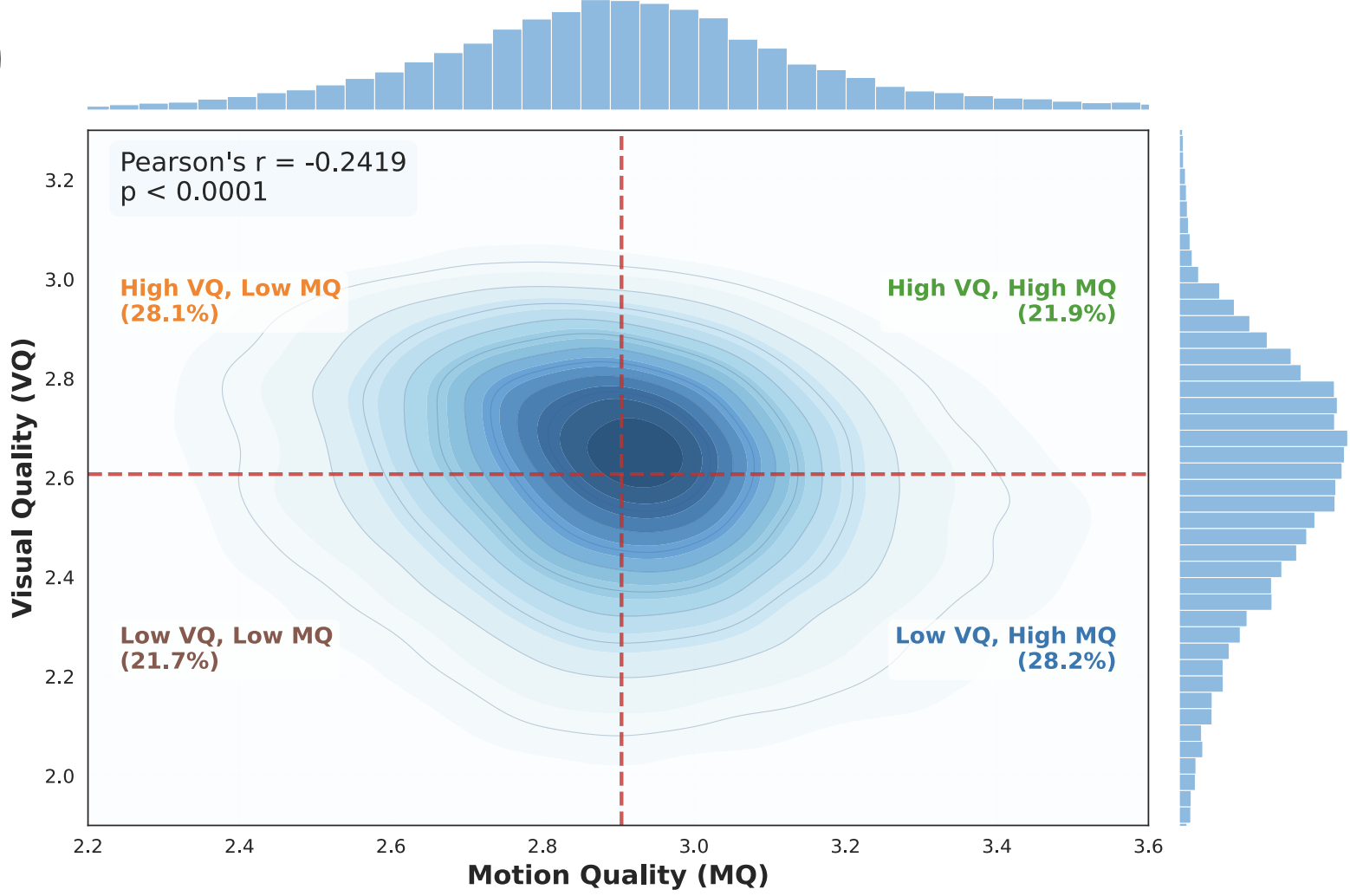
Xiangyang Luo, Qingyu Li, Yuming Li, Guanbo Huang, Yongjie Zhu, Wenyu Qin, Meng Wang, Pengfei Wan, Shao-Lun Huang IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026 [paper] [project] We identify a negative correlation between visual and motion quality in video data and propose Timestep-aware Quality Decoupling (TQD), which leverages timestep-specific sampling to decouple imbalanced data and achieve performance surpassing conventional training with even better data. |
|
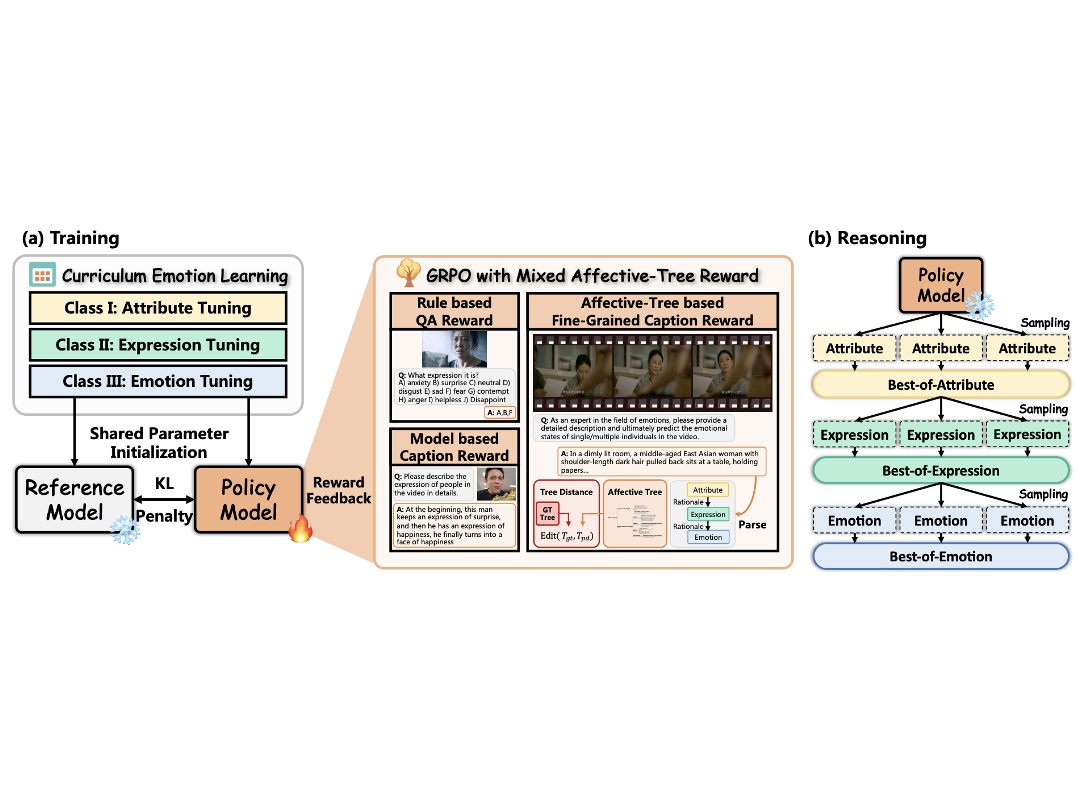
Zhicheng Zhang*, Weicheng Wang*, Yongjie Zhu†, Wenyu Qin, Pengfei Wan, Di Zhang, Jufeng Yang The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025 [paper] [project] We introduce the VidEmo framework and the Emo-CFG dataset, enabling affective cue–guided video emotion understanding and significantly outperforming existing VideoLLMs across multiple video perception tasks. |
|
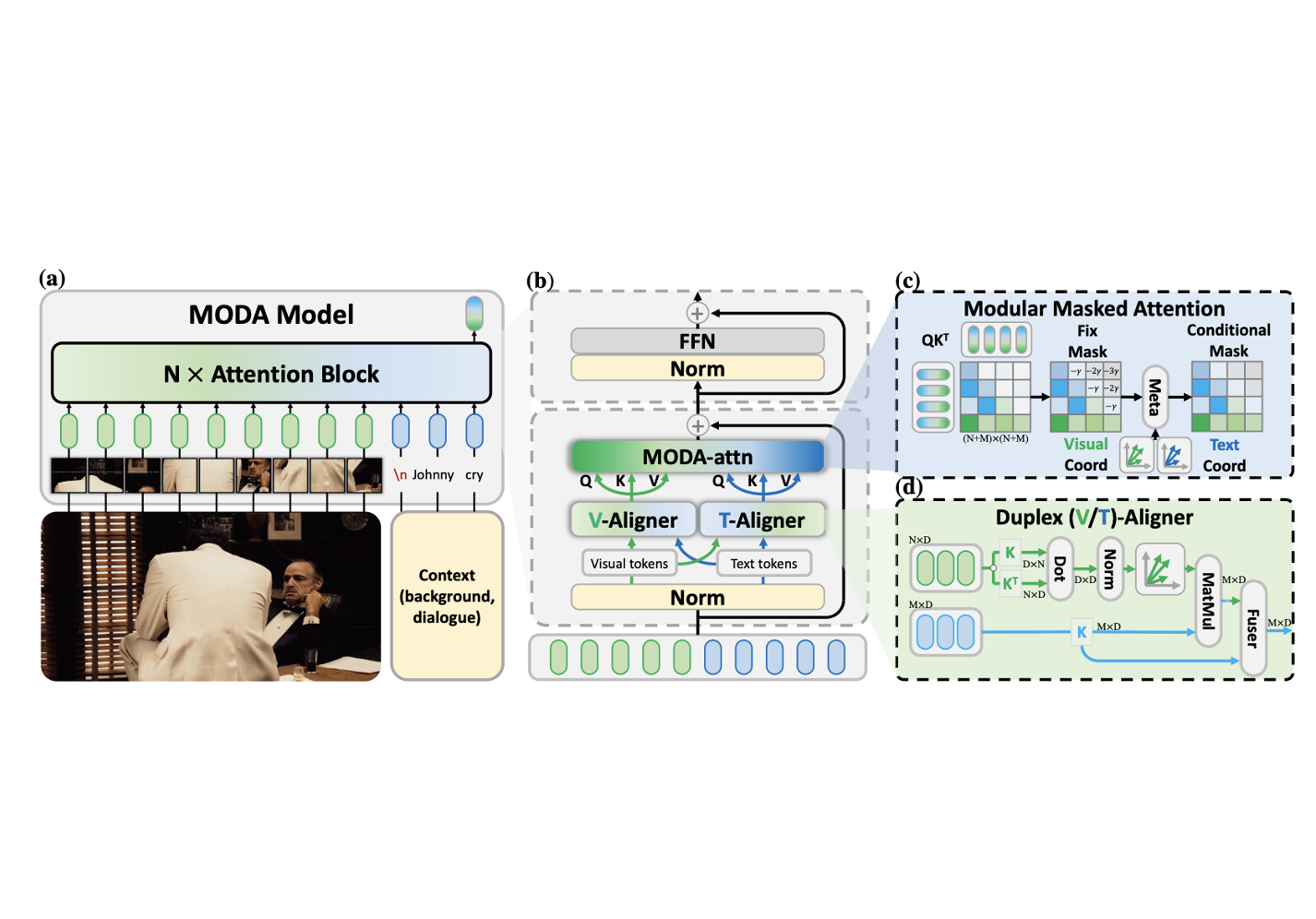
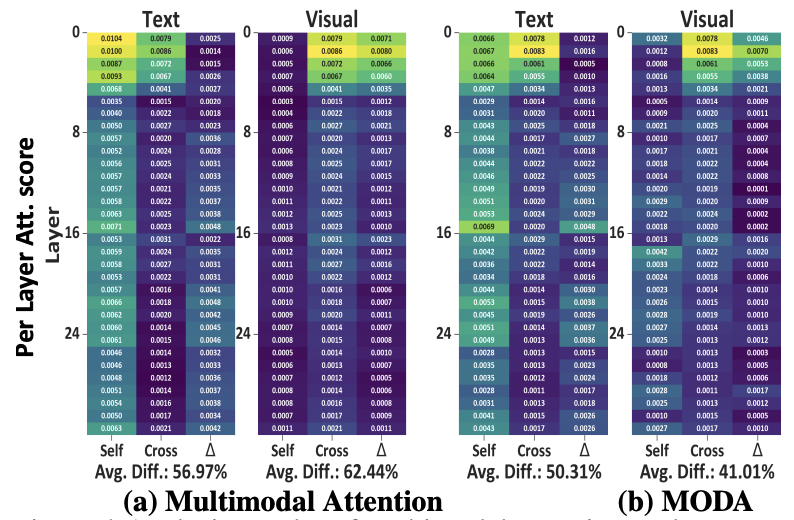
Zhicheng Zhang, Wuyou Xia, Chenxi Zhao, Yan Zhou, Xiaoqiang Liu, Yongjie Zhu†, Wenyu Qin, Pengfei Wan, Di Zhang, Jufeng Yang Forty-Second International Conference on Machine Learning (ICML), 2025 (Spotlight Poster) [paper] [project] A modular attention-empowered Multimodal LLM that delving deep into the fine-grained cues for emotion understanding and cognition analysis. |
 
|
Fan Fei*, Yean Cheng*, Yongjie Zhu, Qian Zheng, Si Li, Gang Pan, Boxin Shi IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023 [paper] [project] This paper proposes a novel pipeline to estimate a non-parametric environment map with high dynamic range from a single human face image. |
|
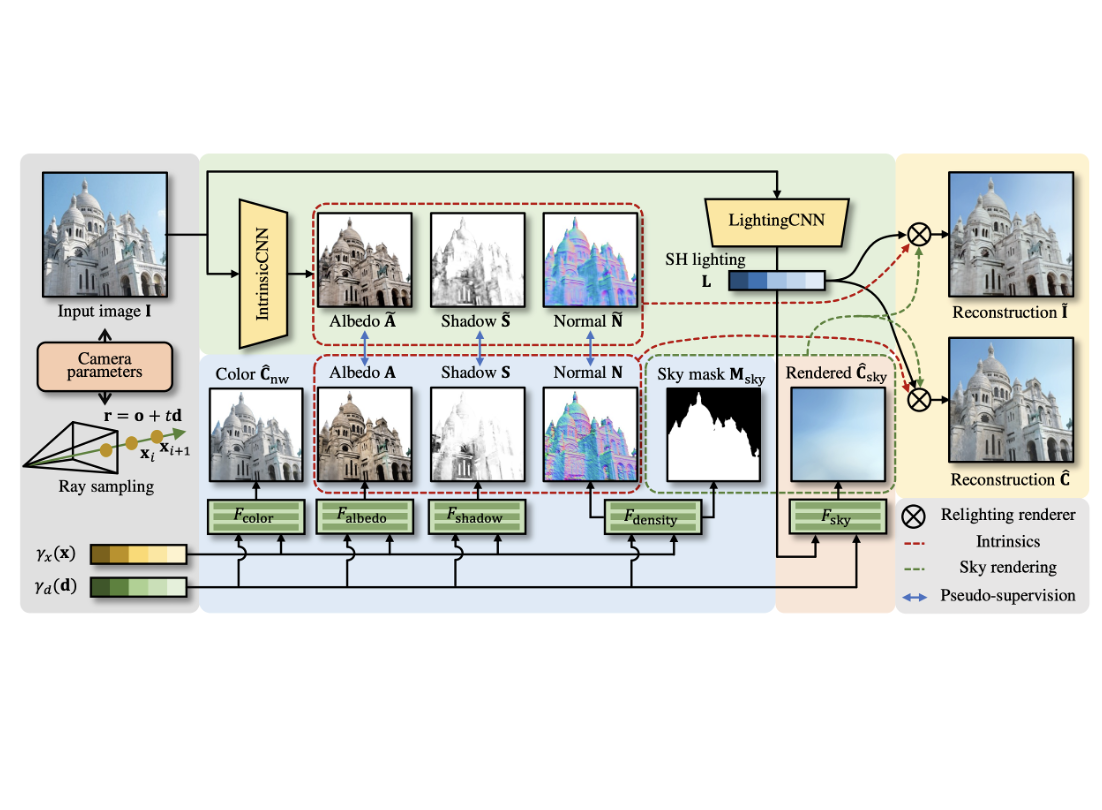
Siqi Yang*, Xuanning Cui*, Yongjie Zhu, Jiajun Tang, Si Li, Zhaofei Yu, Boxin Shi IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 [paper] [supp] [bibtex] This paper proposes to complement the intrinsic estimation from volume rendering using NeRF and from inversing the photometric image formation model using convolutional neural networks (CNNs). |
 
|
Jiajun Tang, Yongjie Zhu, Haoyu Wang, Jun Hoong Chan, Si Li, Boxin Shi European Conference on Computer Vision (ECCV), 2022 (Oral Presentation) [paper] [bibtex] [project] Given a single image and a 2D pixel location, our method can estimate the local lighting that is disentangled into ambient sky light, sun light and lighting-independent local contents. |
|
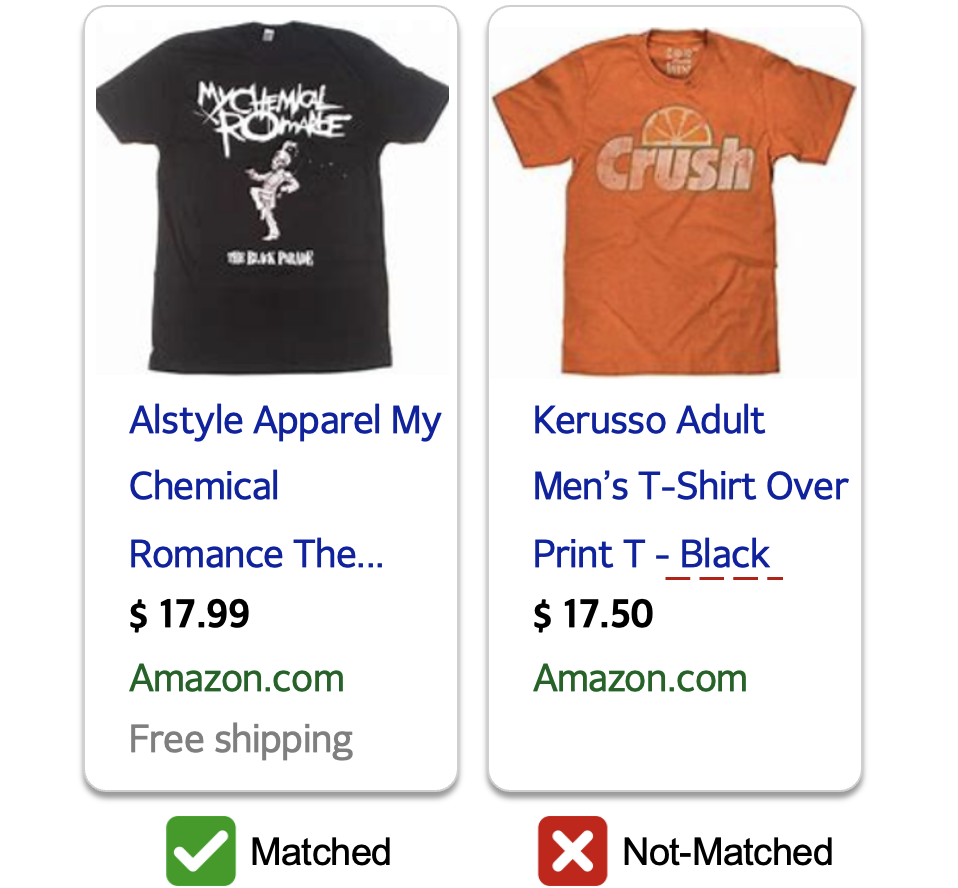
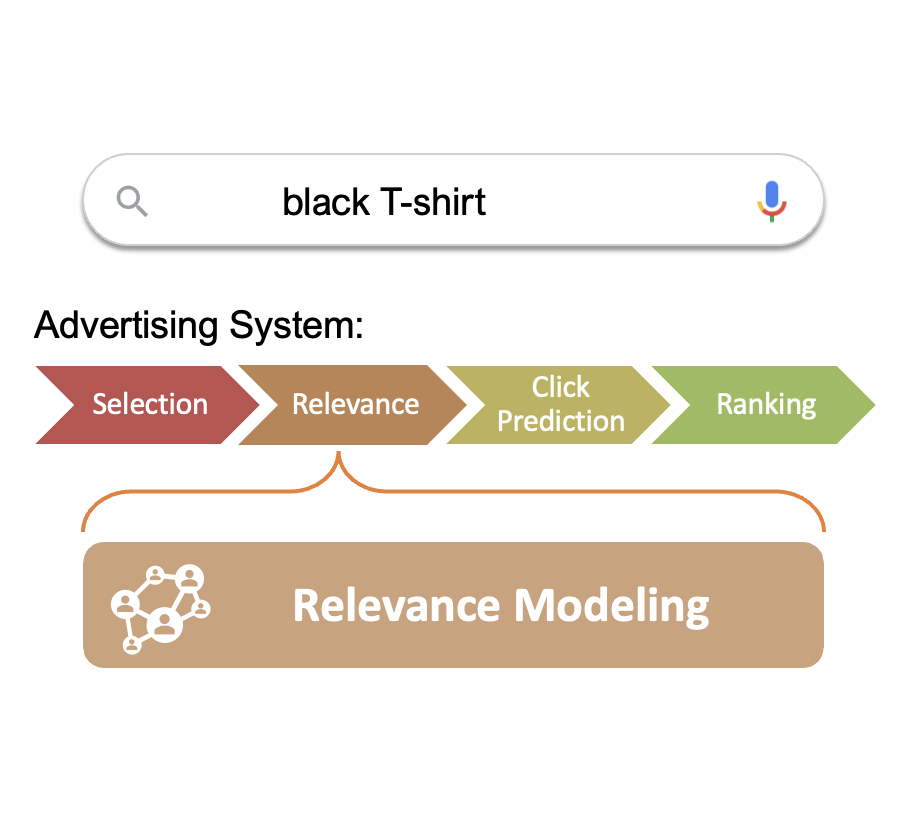
Yongjie Zhu, Chunhui Han, Yuefeng Zhan, Bochen Pang, Zhaoju Li, Hao Sun, Si Li, Boxin Shi, Nan Duan, Ruofei Zhang, Liangjie Zhang, Weiwei Deng, Qi Zhang ACM International Conference on Multimedia (ACM MM), 2022 [paper] [bibtex] [data] We propose a multi-modal relevance modeling approach for sponsored search, and boost the performance via contrastive learning that naturally extends the transformer encoder with the complementary multi-modal inputs. |
 
|
Yongjie Zhu, Chen Li, Si Li, Boxin Shi, Yu-Wing Tai IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021 [paper] [bibtex] [video] We proposed a self-supervised deep learning framework that can estimate the hybrid reflection model and detailed normal of the human face. The proposed hybrid reflectance and illumination representation ensures the photo-realistic face reconstruction. |
|
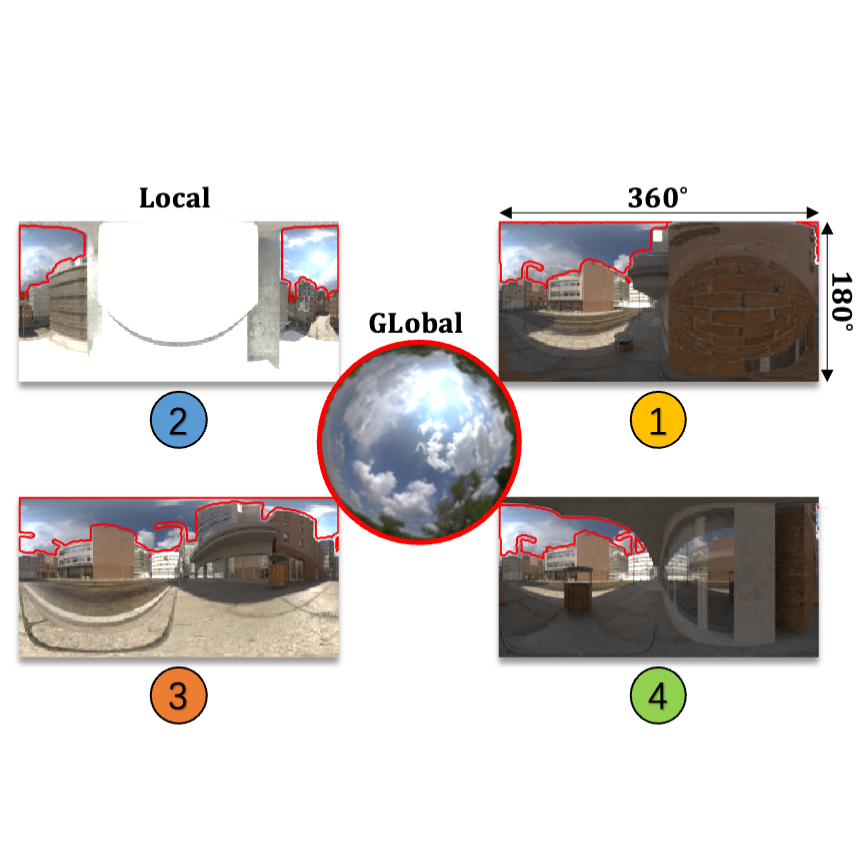
Yongjie Zhu, Yinda Zhang, Si Li, Boxin Shi IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (Oral Presentation) [arXiv] [bibtex] [video] [poster] Collecting high quality paired intrinsic and lighting data in a virtual city lets you train a model that estimates spatially-varying lighting from a single outdoor image. |
 
|
Yongjie Zhu, Jiajun Tang, Si Li, Boxin Shi International Conference on Computational Photography (ICCP), 2021 [arXiv] [bibtex] Decomposing a single RGB image into its reflectance, shading (caused by direct lighting), and shadow (caused by occlusion) images. |
|
|
|
|
Conference Reviewer, CVPR, ICCV, ECCV |
|
|
Journal Reviewer, IJCV, TPAMI |
|
|
|
|
|
|
|
|
|
|
|
|
|
Homepage of Yongjie Zhu [朱勇杰] |